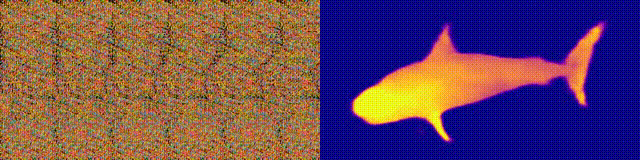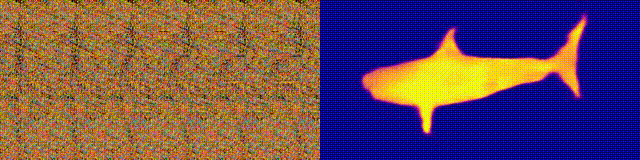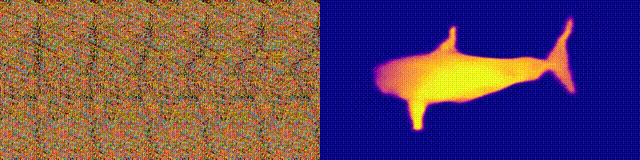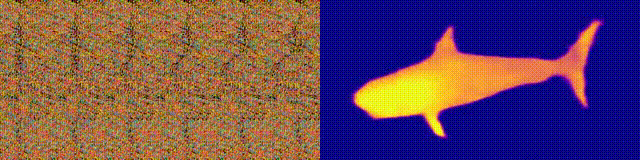
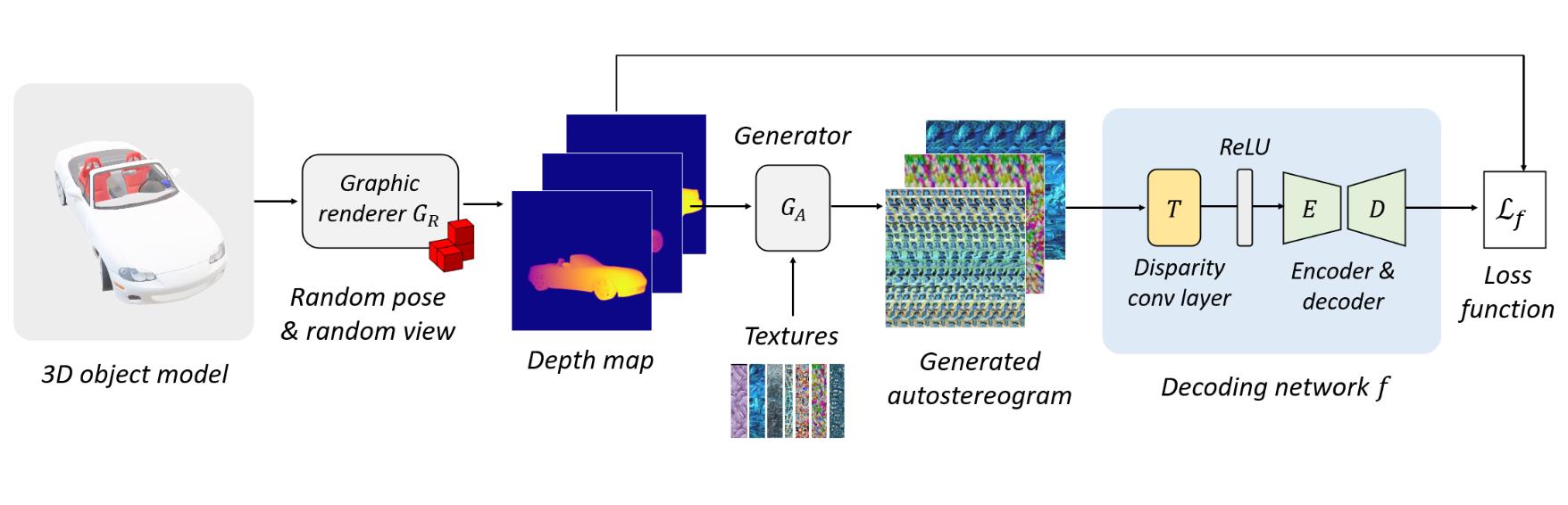
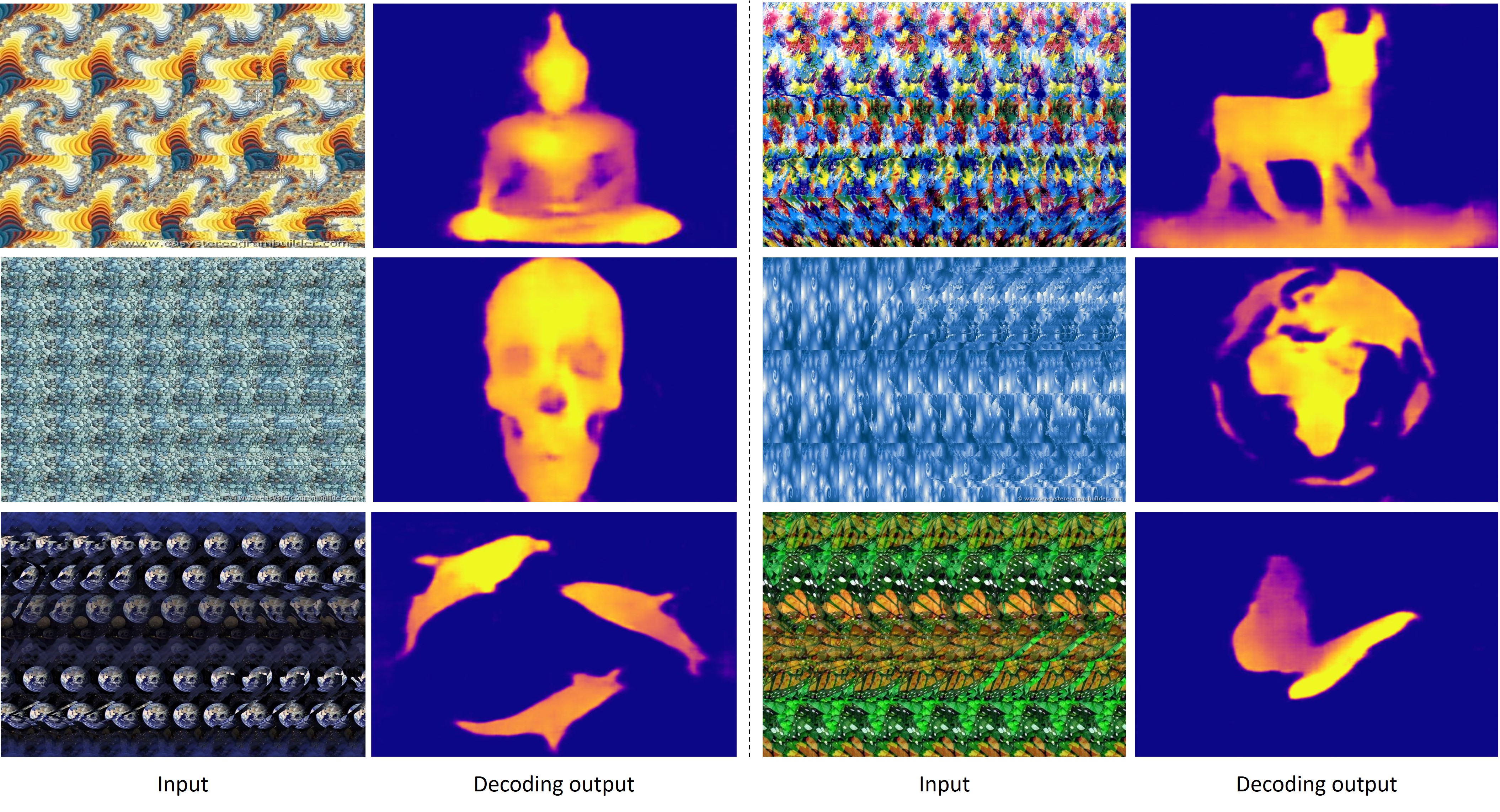
We finally investigated an interesting question
that given a depth image, what an "optimal autostereogram" should look
like in the eyes of a decoding network. The study of this question may
help us understand the working mechanism of neural networks for
autostereogram perception. To generate the "optimal autostereogram", we
run gradient descent on the input end of our decoding network and
minimize the difference between its output and the reference depth
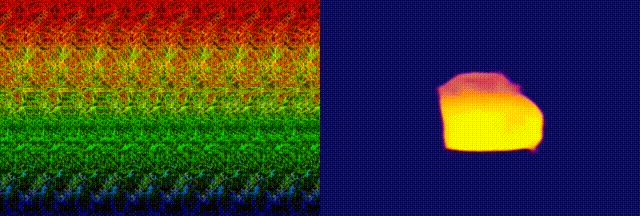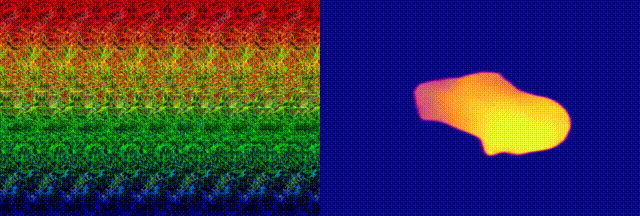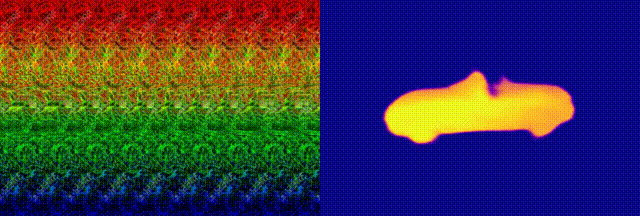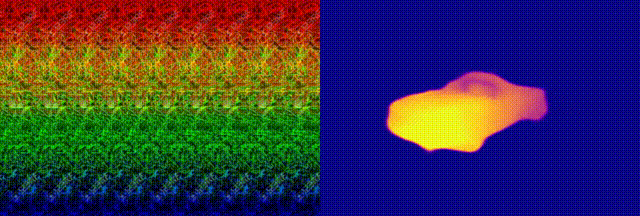
image. In the following example, (a) shows the generated "optimal
autostereogram" on one of our decoding network with an UNet structure.
We named it a "neural autostereogram". In (b)-(c), we show the reference
depth and the decoding output.
An interesting thing we observed during this experiment is that,
although the decoding output of the network is already very similar to
the target depth image, however, human eyes still cannot perceive the
depth hidden in this neural autostereogram. Also, there are no clear
periodic patterns in this image, which is very different from those
autostereograms generated by using graphic engines. More surprisingly,
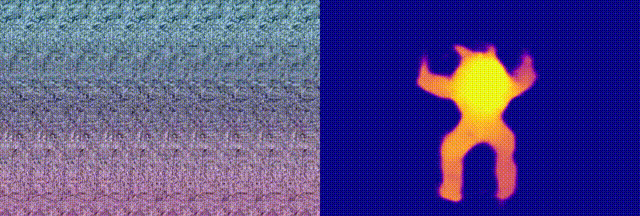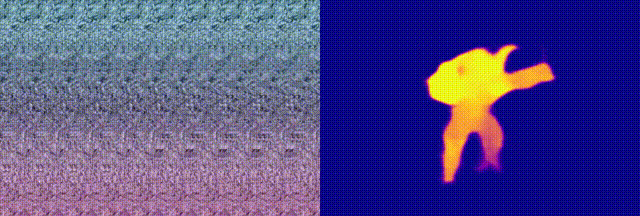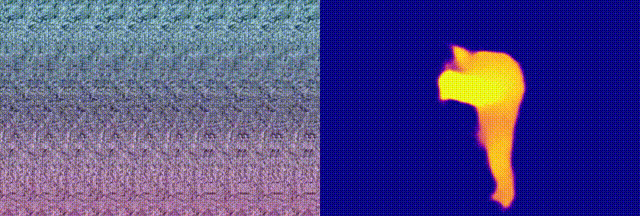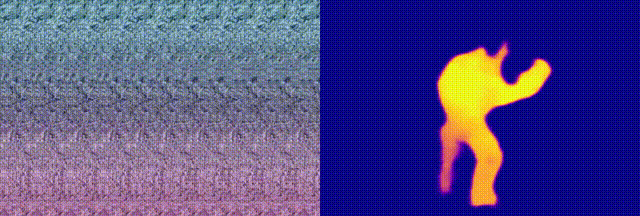
when we feed this neural autostereogram to other decoding networks with
very different architectures, we found that these networks can
miraculously perceive the depth correctly. To confirm that it is not
accidental, we also tried different image initialization and smooth
constraints but still have similar observations. In the following image,
(d)-(f) show the decoding results on this image by using other different
decoding networks. This experiment suggests that neural networks and the
human eye may use completely different ways for stereogram perception.
The mechanism and properties behind the neural autostereograms are still
open questions and need further study.