Rocket-recycling with Reinforcement Learning
University of Michigan, Ann Arbor
As
a big fan of SpaceX, I always dreamed of having my own rockets.
Recently, I worked on an interesting question that whether we can
"build" a virtual rocket and address a challenging problem - rocket
recycling, with simple reinforcement learning. I tried on two
tasks: hovering and landing. Since it is my first reinforcement learning
project, I tried to implement everything from scratch as much as
possible, including the environment, rocket dynamics and the RL agent. I
hope that through these low-level coding, I can have a deeper
understanding of the of reinforcement learning, including the basic
algorithms, the interaction between the agent and the environment, and
the design of rewards.
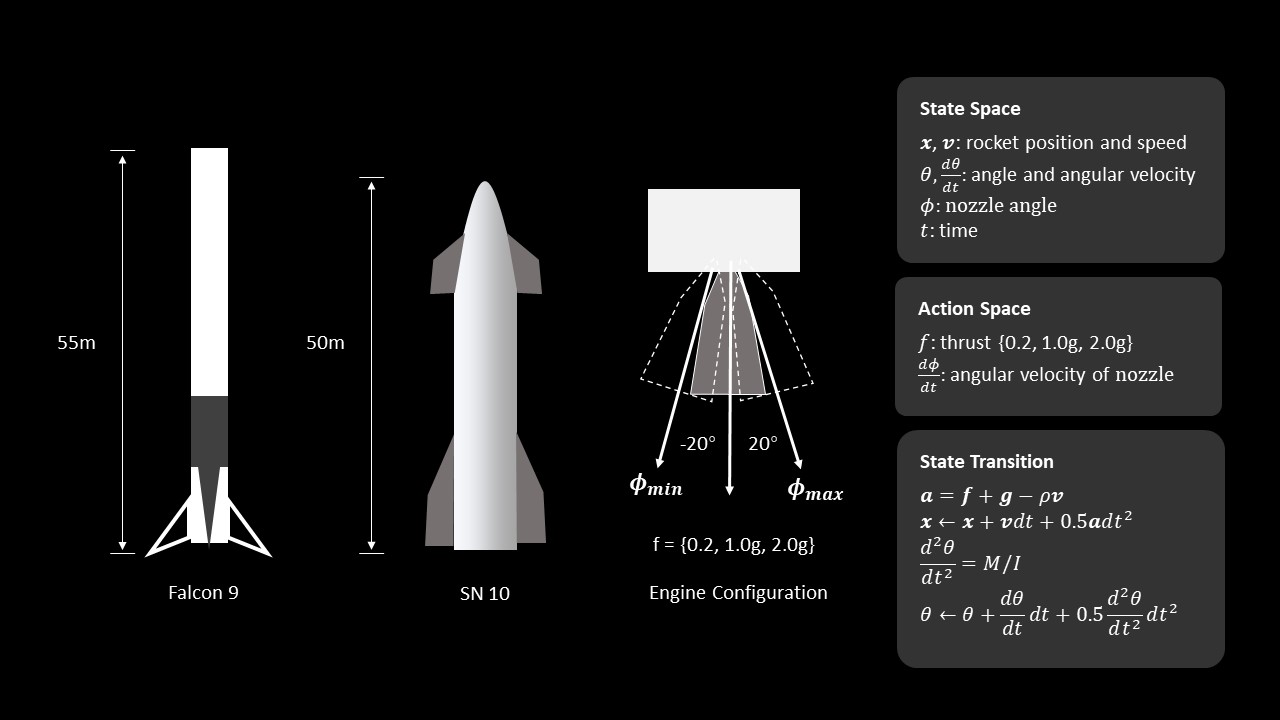
The rocket is simplified into a rigid body on a 2D
plane. I considered the basic cylinder dynamics model and assumed the air
resistance is proportional to the velocity. A thrust-vectoring engine is
installed at the bottom of the rocket. This engine provides adjustable
thrust values (0.2g, 1.0g, and 2.0g) with different directions. An angular
velocity constraint is added to the nozzle with a max-rotating speed of 30
degrees/second. With the above basic settings, the action space is defined
as a collection of the discrete control signals of the engine, including
the thrust acceleration and the angular velocity of the nozzle. The
state-space consists of the rocket position, speed, angle, angle velocity,
nozzle angle, and the simulation time.
For the landing task, I followed the basic parameters
of the Starship SN10 belly flop maneuver. The initial speed is set to
-50m/s. The rocket orientation is set to 90 degrees (horizontally). The
landing burn height is set to 500 meters above the ground. For the
hovering task, the rocket is released at a height of 300 meters with a
vertical speed of -10m/s and a orientation of 45~135 degrees (-45~+45
degrees vertically).

Image credit
https://twitter.com/thejackbeyer/status/1367364251233497095
The reward functions are quite straightforward.
For the hovering tasks: the step-reward is given based on two rules: 1)
The distance between the rocket and the predefined target point - the
closer they are, the larger reward will be assigned. 2) The angle of the
rocket body (the rocket should stay as upright as possible)
For the landing task: we look at the Speed and angle at the moment of
contact with the ground - when the touching-speed are smaller than a safe
threshold and the angle is close to 0 degrees (upright), we see it as a
successful landing and a big reward will be assigned. The rest of the
rules are the same as the hovering task.
I implemented the above environment and train a
policy-based agent (actor-critic) to solve this problem. The episode
reward finally converges very well after over 20000 training episodes. The
following GIFs show the learned RL behavior over number of training
episodes.
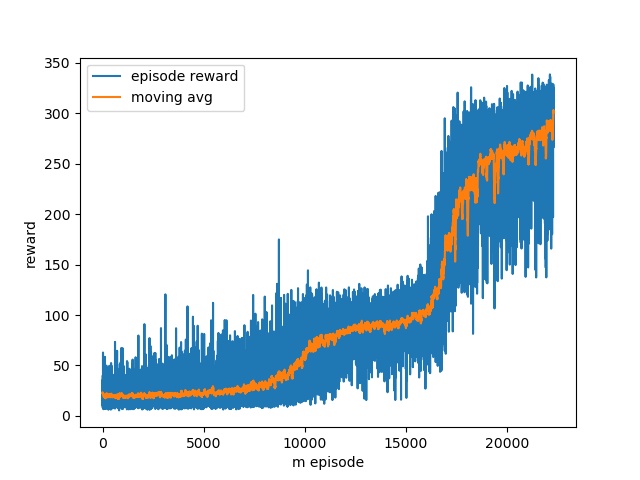
Reward over number of training
episodes (hovering task)
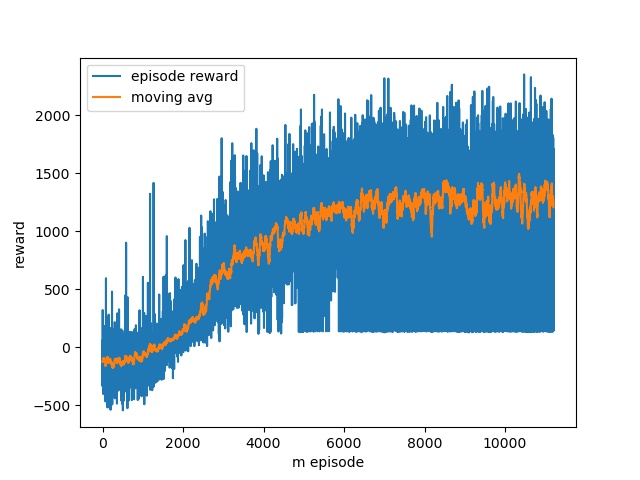
Reward over number of training
episodes (landing task)

Training episode 0 (random agent)

Training episode 1000

Training episode 2000

Training episode 10000
Finally, after 20000 training episodes

Fully trained agent (task: hovering)

Fully trained agent (task: landing)
Despite the simple setting of the environment and
the reward, the agent has learned the belly flop maneuver nicely. The
following animation shows a comparison between the real SN10 and a fake
one learned from reinforcement learning.
@misc{zou2021rocket,
author = {Zhengxia Zou},
title = {Rocket-recycling with Reinforcement Learning},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished =
{\url{https://github.com/jiupinjia/rocket-recycling}}
}
